<개요>
- 이런 질문을 들었다. Server를 설계할 때 user가 100명이라면 어떻게 만들 것인가? 1000명이라면? 1만명이면?
** AWS의 Auto Scaling 은 고려하지 않는다. (Cost 관리 및 User 증가에 따른 DB의 I/O 속도 감소를 제어 불가)
[1~100]
- Traffic 을 고려하지 않아도 됨.
- 서비스 Application 과 Database를 직접 연결
- 서버 Application 에서 request를 받고, db를 local에 호출하여 결과를 보냄
[100~1K]
- 항상 일정한 수의 user가 들어오면 Scale up(수직 확장, 서버 스펙 업그레이드) 을 한다.
- 불규칙하게 들어오면 Scale out(수평 확장, 서버 수 증가) 를 한다.
- Scale out 을 할 경우, Load Balancing를 통해 Traffic 관리를 함.
==> Load Balancing을 하면 db 일관성이 깨진다.(server_1에 로그인 정보, server_2 에 로그인 요청이 들어가면?)
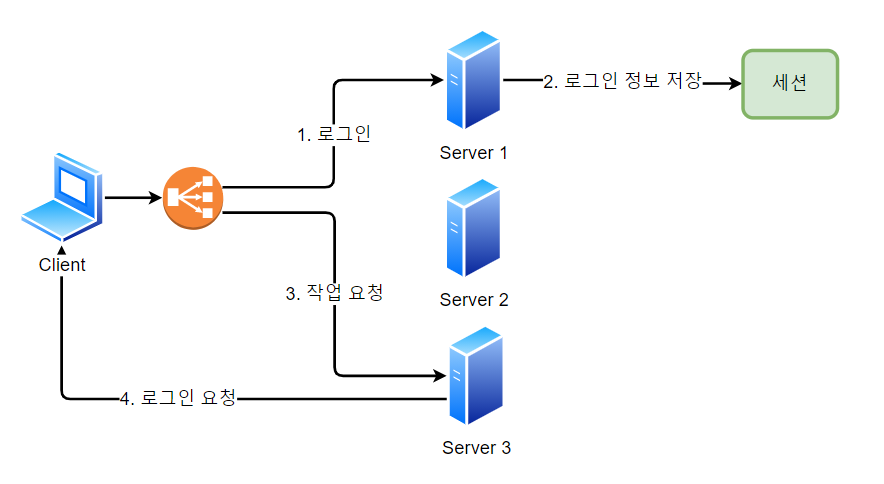
==> db 일관성 문제는 각 Server 마다 고유한 session을 가짐이 아닌, Server 공용의 session store을 두어 해결
==> Session store 을 분리하여 모든 Server가 하나의 store를 공유하고 데이터 정합성을 유지함.
@@ 데이터 정합성 : data들의 값이 서로 일치함
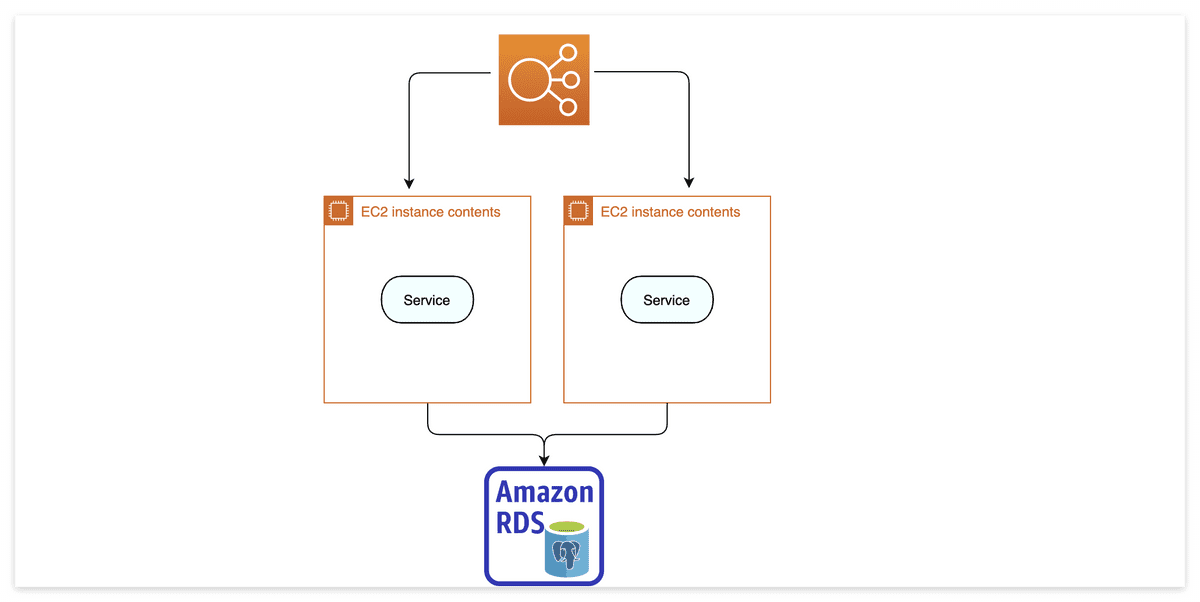
==> Session store 을 통해 Server는 session 상태를 가지지 않아 지속적으로 확장이 가능
==> 1개의 Server에서 장애가 발생하여도 Session store에는 영향이 없으므로 다른 Server에서 작업 처리 가능.
==> Session을 복제하여 발생하는 것 보다 network 비용이 훨씬 적게 듦
[1K ~ 10K]
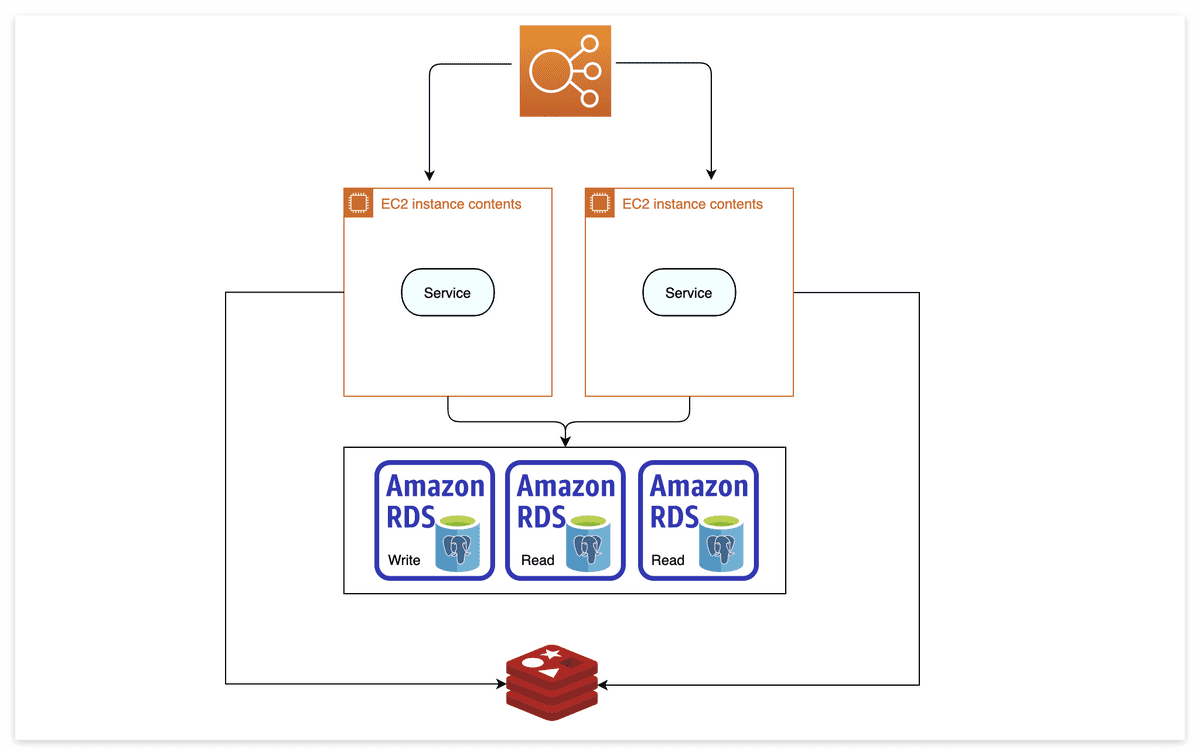
- Server Application이 100인데 DB store는 1개 라면 문제이므로, DB store를 늘린다.
- data 일관성을 위해 쓰기용 DB 1개를 두고, 나머지는 읽기용 DB 로 복제 (DB 기능 Partitioning)
- 무작정 DB 만 늘리는건 cost가 높다. 자주 바뀌지 않는 data (user 입장에서 없어져도 피해가 적은, session 등) 들은 DB 로 연결하는 대신 Redis (메모리 캐시) 를 써서 빠르게 가져올 수 있다.
[10K ~ 100K]
- CDN (Content Delivery Network)
==> 지리적으로 분산된 여러 개의 Server. web contents 를 사용자와 가까운 Server에서 전송하여 전송 속도 증대.
==> ex) ATM(server) 이 사방에 있어 user가 자기와 가까운 곳에서 돈을 인출하여 시간을 아끼는 개념.
==> 사이트의 정적 resource 들을 빠르게 서빙
[100K ~ 1M]
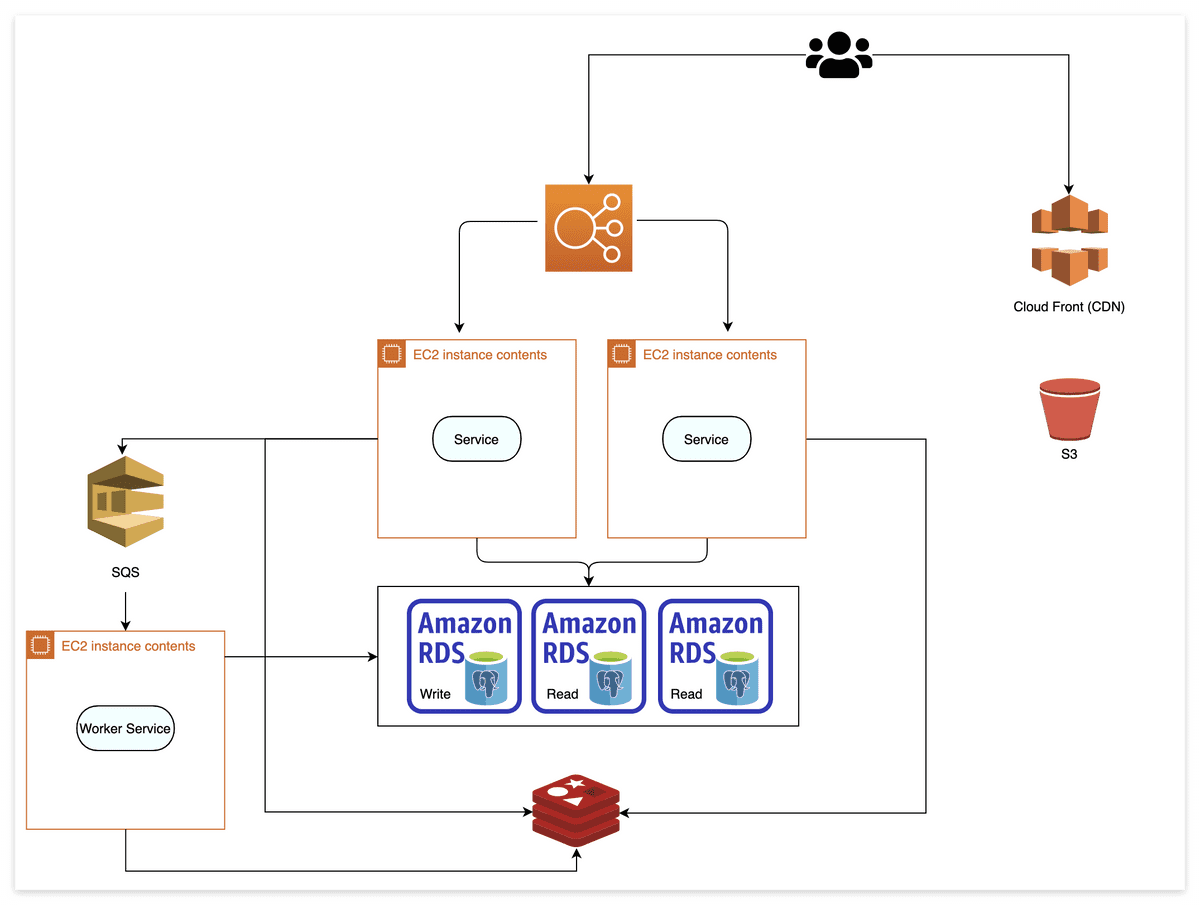
- data 동기화 문제로 '쓰기 DB'는 1개만 사용했었음. 그러나 100K 가 넘어가면 동시에 많은 user가 쓰기를 할 수 있어 DB에 무리가 감
==> Messaging Queue 를 통해 해결
==> Server에서 바로 DB로 연결하지 않고 Messaging Queue로 요청을 넘긴 뒤, Worker Server가 polling하며 차례로 처리
==> User가 선택한 옵션에 따라 순서를 보장할 수도, 아닐 수도 있음.
==> Worker Server도 마찬가지로 수직&수평 확장이 가능.
<확장판>
100K가 넘어가는걸 전제로 미리 DB sharding이나 Partitioning을 하는 것도 방법이다.
** [DB sharding]
- 여러개의 병렬 database에 걸쳐 data를 분할하고, 각 database에 비즈니스의 한 segment를 저장.
- 즉 같은 형태의 database 를 여러개로 복붙한 구조. database의 자기복제를 통해 확장하기 용이.
- DB Horizontal Partitioning 과 같은 개념.
- Sharding 종류 :
1) Modular Sharding
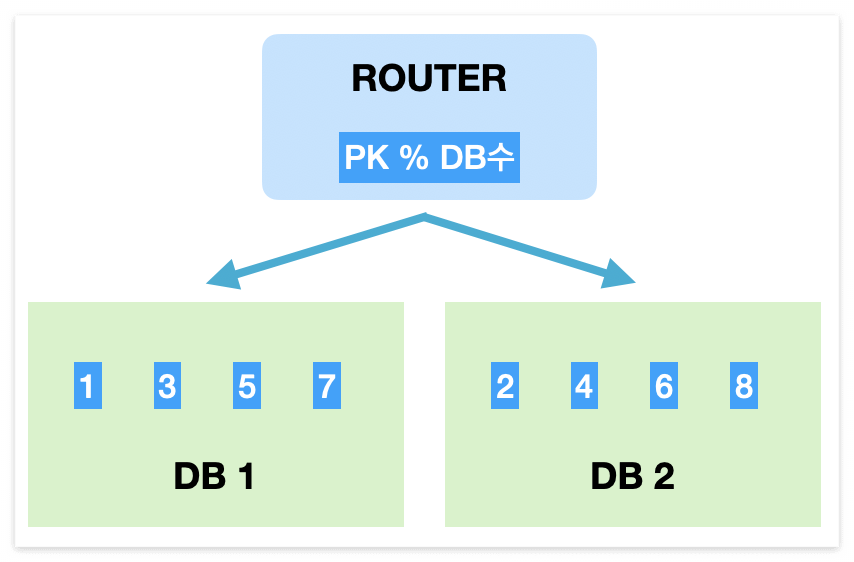
==> 장점 : Range Sharding에 비해 data가 균일하게 분산
==> 단점 : DB를 추가하면 이미 DB에 들어간 data를 재정렬 해야함
==> data 양이 일정하게 유지될 때 적합. data가 꾸준하지만 적재 속도가 빠르지 않으면 써볼만 함
2) Range Sharding
==> 장점 : Modular Sharding에 비해 DB 추가에 따른 재정렬 cost 발생 X
==> 단점 : 일부 DB에 data가 몰릴 수 있음 (과부하 예상)
==> data가 급격히 증가할 수 있다면(이벤트 등) DB 확장 cost가 없으므로 써볼만 함.
- sharding 조건
==> 각 shard의 data 용량이 비슷하고, 각 shard에서 비슷한 속도로 data가 증가해야함.
==> 각 shard에 대한 초당 연결 수가 거의 동일해야함.
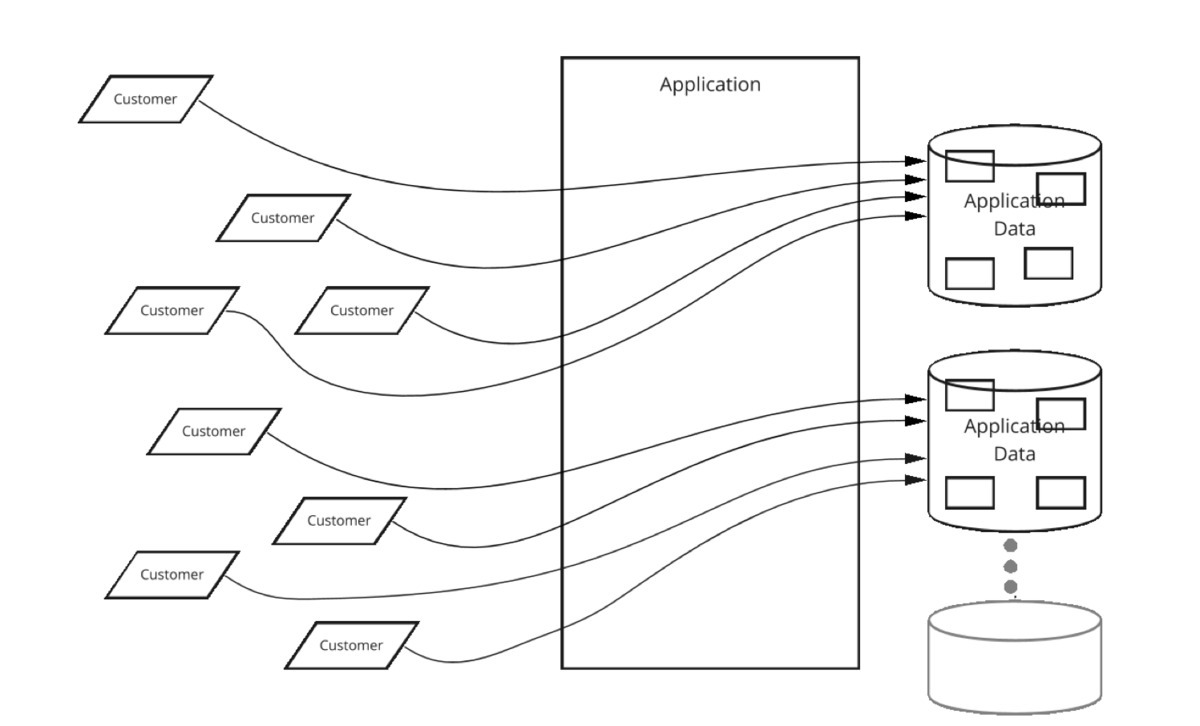
- 그러나 Sharding 을 함부로 도입하면 안되는 이유가 있다.
1) 고객(User)의 application 사용량이 증가. (양적 증가)
2) 고객이 더 많은 storage 사용 및 resource를 소비. (질적 증가)
3) 어느 순간 shard(복제된 db) 에 과부하가 걸리면 load가 상대적으로 적은 shard로 고객의 db를 옮겨야 함.
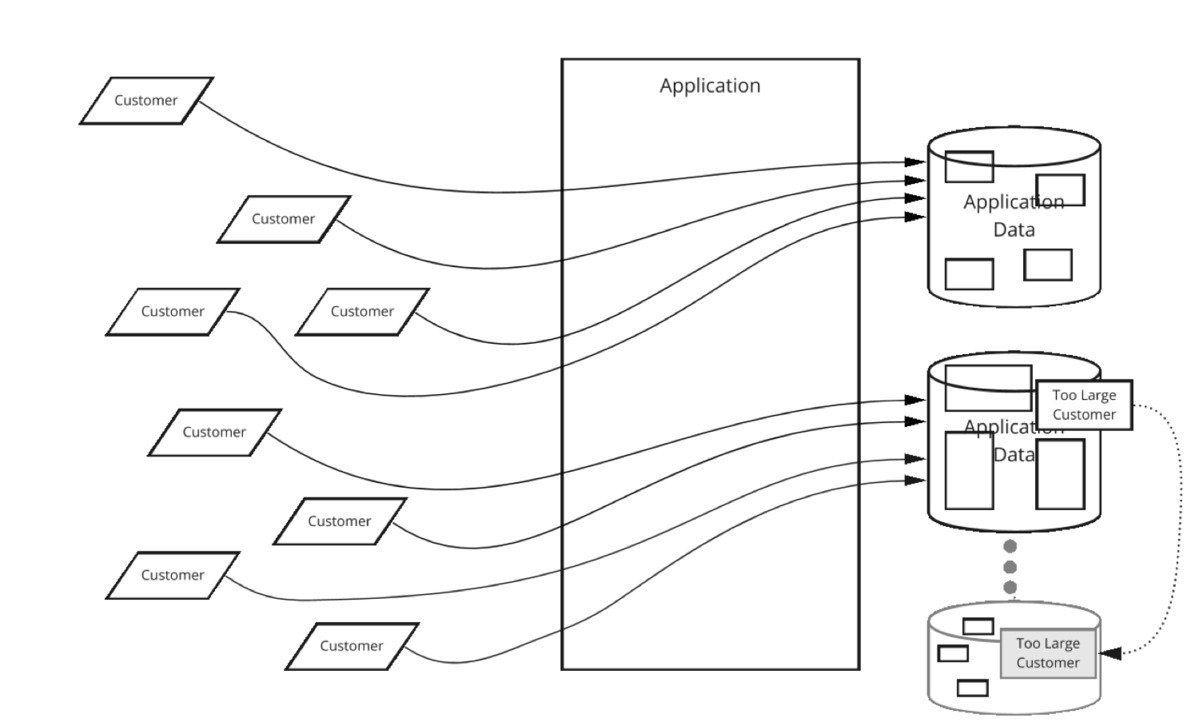
그러나 고객의 size가 너무 커서 옮길 곳이 없다면? Sharding 으로 해결 불가. 다운타임 발생.
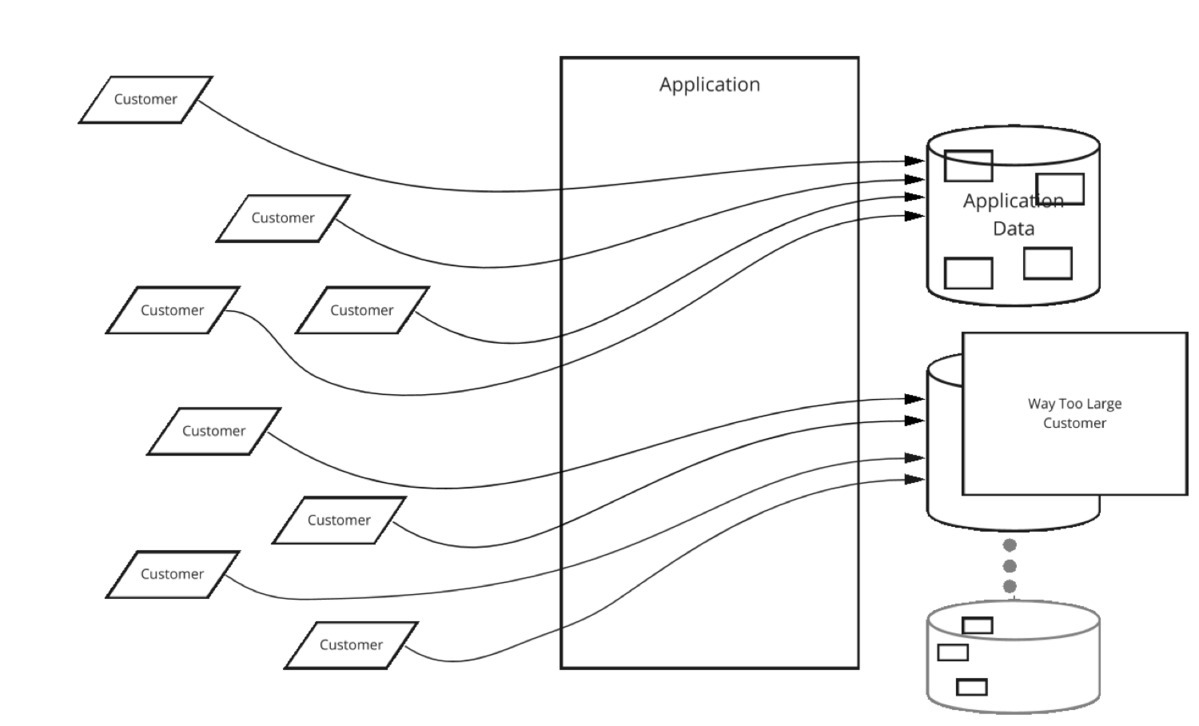
==> Sharding 과부하 발생시 Repartitioning, Rebalancing, 편중된 사용, Cross-shards reporting, Partition 된 분석 문제 등에 대응해야 함.
- 이런 위험성에도 Shard를 사용해야만 한다면?
1) 필요한 시점보다 훨씬 이전에 Shard 를 설정 (초기 설계부터 Shard를 고려)
2) Sharding Key 를 신중하게 선택. Shard는 독립적인 동시에 균형이 맞아야 하므로, 단순히 ID로 Sharding Key를 삼지 말고 비즈니스 로직이나 요구사항에 맞춰 Key 를 설정한다.
3) Sharding 을 Production에 구현하기 전에 Shard를 관리하기 위한 Tool 을 구축 및 Shard 크기 조정에 이상이 있을 때 알릴 분석(모니터링 tool)이 필요.
==> Tool 은 Sharding 된 개별 요소(고객 등)를 Shard에서 다른 Shard로 투명하고, 빠르며, 효율성있게 옮겨야 함.
==> Tool 은 Shard에 과부하 장애 발생시, 여러 resource를 신속하게 Rebalancing 해야 함.
** [DB Vertical Partitioning]
- 자주 access 하는 항목을 가져오는 것과 연관있는 I/O 및 성능 저하 를 줄이는데 쓰임
- 예를들어 칼럼 구성이 name, pwd, email 이다. 만약 email 만이 대량 호출된다면 같은 key값으로 email 칼럼만을 쪼개고 다른 DB에 저장하여 Traffic 을 줄인다.
** [Traffic 이 갑작스레 너무 몰릴 경우 대비]
- Kafka 사용
==> producer/consumer 구조
==> Producer에서 broker에 몇 개의 메세지를 가져와 처리할 지 결정
==> 만약 Server가 죽어도 이미 broker에서는 이미 메세지를 가지고 있을 것이기에 Load Balancing 을 통해 다른 Server에서 알아서 처리할 것 임.
==> 만약 처리 도중에 Server가 죽더라도 Kafka 는 메세지를 disk에 처리하고, 실패할 경우 해당 메세지에 대해 다시 처리.
==> 장애 발생시, 장애가 일어난 시점부터 재처리 가능
** [Process 를 이용한 packet 처리 향상]
- 다수의 Core Process 를 활용하여 System Resource 를 최대한 활용
- Multi-Processing 을 통해 각 Node의 작업부하를 균등하게 유지하여, 작업 대기시간 감축 및 각 작업의 수행 시간을 최소로 만듦
<기타 설계>
** [모니터링]
- 에러로그 모니터링. System/Application의 장애를 탐색
- Prometheus & Grafana 활용
- Datadog 활용 (22년 기준, 한국 DevOps 들이 가장 많이 씀)
** [메트릭]
- System의 현재 상황 파악.
- 호스트 단위 메트릭 : CPU, 메모리, 디스크 IO
- 종합 메트릭 : DB 계층 성능, 캐시 계층 성능
- 핵심 비즈니스 메트릭 : 일별 능동 사용자(DAU)
** [자동화]
- CI/CD
- 빌드/테스트/배포 절차 자동화 를 통해 개발 생산성 향상 (Jenkins 활용)
- Docker 활용 : Container를 통해 각 서비스를 객체화하여 한 로직이 망가져도 다른 쪽에 피해가 가지 않게 함
- Kubernetes 활용 : k8s라고도 함. Docker 등의 Container 를 관리.
<출처 2> https://hojak99.tistory.com/640
<출처 3> https://jaesika.tistory.com/2
<출처 4> https://www.itworld.co.kr/news/200134
<출처 5> https://koreascience.kr/article/CFKO202022449680353.pdf
<출처 6> https://techblog.woowahan.com/2687/
<출처 7> https://docs.microsoft.com/ko-kr/azure/architecture/best-practices/data-partitioning
<출처 8> https://www.quora.com/Whats-the-difference-between-sharding-DB-tables-and-partitioning-them
<출처 9 > 작성자 머리
'Programing > Web' 카테고리의 다른 글
| [Web] Cookies (쿠키) (0) | 2022.08.23 |
|---|---|
| [Web] Web 동작 방식 (0) | 2022.08.22 |
| [Web] Rest API (0) | 2022.06.20 |
| [Web] URI, URL, URN 특징 및 차이 (0) | 2022.06.06 |
댓글