<OS 특징>
[OS System 의 핵심 요소]
1) Abstraction :
==> Process, Thread, File, Socket, Memory
2) Mechanism :
==> Create, Schedule, Open, Write, Allocate
3) Policy :
==> LRU, EDF
[OS 설계 원리]
1) Seperation of mechanism and policy
==> 정책 지원을 위한 유연한 Mechanism 구현
2) Optimization for common case
==> OS 가 어디에 사용되는가?
==> User가 그 기계로 뭘 Execute 하길 원하는가?
==> Workload 요구사항은 무엇인가?
[OS Type]
1) Monolithic OS
==> 전체 OS 가 Kernel 공간에서 작동하며, Supervisor Mode 에서 혼자임(?)
2) Modular OS
==> System Core 의 일부가 Module이란 독립된 File 에 위치 가능함.
==> Module은 Run Time 할 때 System에 추가할 수 있음.
3) Micro OS
==> Kernel 이 Server라 불리는 별도의 Process로 쪼개짐.
==> Server 의 일부는 Kernel 공간에서 동작하고, 일부는 User-공간 에서 일함.
<OS 핵심 개념>
[1. Processes and Process Management]
- Process 는 기본적으로 Execution 중인 Program.
- Process 의 싱행은 반드시 순차적인 과정에서 진행함.
- Program 이 Memory로 Load 되어 Process 가 되면 4부분으로 나눠짐.
==> Stack, Heap, Text, Data
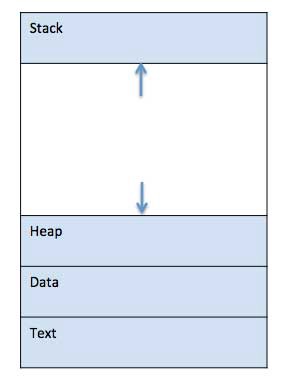
- 위 이미지는 Main Memory 내부의 Process 구조
==> Stack : Method/Function Parameter, Return 주소, Local 변수 같은 Temporary Data 를 가짐
==> Heap : Run-Time 동안 Process에 동적으로 할당되는 Memory.
==> Data : Global 및 Static 변수를 가짐.
==> Text : Program Count 값으로 표시되는 현재 활동과 Processor의 Register 내용이 들어감.

- 위 이미지는 Process Execute 할 때 OS 의 일반적인 상태를 나타낸 것.
* Start :
==> Process가 시작하거나 생성될 때의 초기 상태.
* Ready :
==> Process 가 프로세서에 할당되길 기다림. 할당되어야 작동함.
==> Process는 Start 상태 직후 이 상태가 되거나,
Process를 실행 중일 때 CPU를 다른 Process에 할당하려는 Scheduler에 의해 중단될 수 있음.
* Running :
==> OS Scheduler에 의해 Process가 프로세서에 할당되면,
Process 상태를 Running으로 설정되고 프로세서는 명령을 Execute 함.
* Waiting :
==> Process가 Resource를 기다릴 필요가 있으면 Waiting 상태로 이동.
==> Waiting Resource 는 User의 Input 이나 File이 사용가능해지는 것 등.
* Terminated or Exit :
==> Process 가 Execution을 마치거나 OS에 의해 종료되면,
Main Memory에서 제거되길 기다리는 Terminated 상태로 이동.
- Process 제어 Block은 모든 Process가 OS System에 의해 유지관리되는 Data 구조.
- PCB 는 정수 Process ID(PID)로 식별되며, Process를 추적하는데 필요한 모든 정보를 유지.

- Process 추적에 필요한 각 정보의 특징은 아래와 같다.
* Process State
* Process Privileges :
==> System Resource 에 대한 Access 허용/금지 에 필요.
* Process ID :
==> OS의 각 Process에 대한 고유 식별
* Pointer :
==> Parant Process 로의 Pointer
* Program Counter :
==> 이 Process에 대해 실행될 다음 명령의 Address에 대한 Pointer.
* CPU Register :
==> Running 상태의 Execute를 위해 Process를 저장해야 하는 다양한 CPU Register.
* CPU Scheduling Information :
==> Process Schedule에 필요한 Process 우선순위와 다른 Scheduling 정보.
* Memory Management Information :
==> OS에 쓰일 Memory에 의존하는 'Page 테이블, Memory 제한, Segment Table' 등의 정보를 가짐.
* Accounting Information :
==> Process 실행, 시간 제한, Execution ID 등에 쓰이는 CPU Amount(양)을 가짐.
* IO Status Information :
==> Process에 할당된 I/O 장치들의 목록
[2. Thread and Concurrency]
[Thread 설명]
- Thread는 Process Code를 통한 Execution의 흐름.
- 다음에 Execute 할 명령을 추적하는 자체 Program Counter가 있음.
- 현재 작업 변수를 가진 System Register와 실행기록을 포함하는 Stack을 가짐.
- Thread 는 Code Segment, Data Segment, Open File 과 같은 다양한 정보를 Peer Thread와 공유.
- 어떤 Thread 가 Code Segment Memory Item을 바꾸면 다른 모든 Thread가 이를 확인함.
- Thread는 Lightweight(경량) Process라고도 불림.
- Thread는 Parallelism을 통해 Application 성능을 향상시킴.
- Thread는 Overhead를 줄여 OS 성능을 향상시키는 Software 접근 방식을 함.
- Thread는 정통적인(Classical) Process와 동등함.
- 각 Thread는 정확히 하나의 Process에 속하며, 어떤 Thread도 Process 밖에서 존재할 수 없음.
- 각 Thread는 제어흐름이 서로 겹치지 않고 구별됨.
- Thread는 Network Server 및 Web Server 구현에 매우 훌륭히 사용됨.
- 공유 Memory Multi-processor 에서 Application의 병렬 Execution을 위한 적절한 기반을 제공.
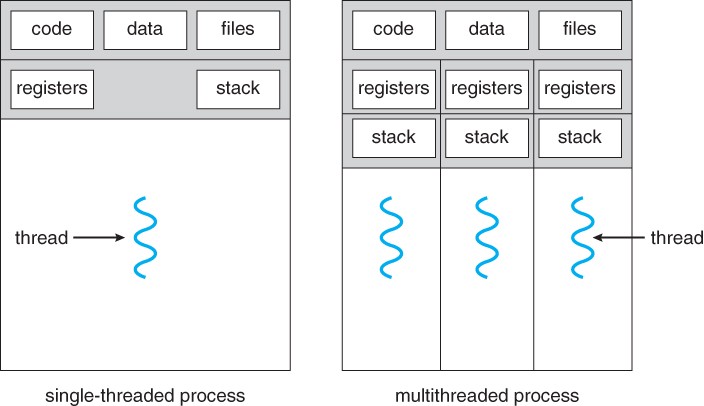
[Thread 이점]
- Context 전환 시간을 최소로 함.
- Process 내에 Concurrency(동시성) 제공
- 효율적인 통신 제공.
- Thread 를 만들고 Context를 전환하는게 더 경제적
- 다중 프로세서 Architecture를 더큰 규모와 효율성으로 활용 가능
[Thread 작동 방식]
- Thread는 2가지 방식으로 Implement(실행) 됨
1) User Level Threads : 사용자 관리 Thread
2) Kernel Level Threads : OS Core의 Kernel에서 작동하는 OS 관리 Thread
[1. User Level Threads]
- 여기서 Thread 관리 Kernel은 Thread의 존재를 인식 못 함.
- Thread Library는 Thread 간 Message 및 Data 전달, Thread 실행 예약,
Thread Context 저장 및 복원, Thread 생성&파괴를 위한 Code를 가짐.
- Application은 Single Thread로 시작함.
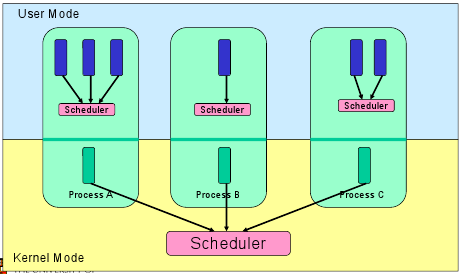
- User Thread 장점
* Thread 전환에 Kernel Mode 권한이 필요 없음.
* 어느 OS 든지 동작.
* Scheduling이 Application에 따라 다를 수 있음
* 생성 & 관리가 빠름
- User Thread 단점
* 전형적인 OS에서 대부분의 System은 Blocking을 호출
* Multi-Thread Application은 Multi-Processing의 이점이 없음
[2. Kernel Level Threads]
- Thread 관리가 Kernel에 의해 이뤄짐.
- Application 영역에 Thread 관리 Code가 없음.
- Kernel Thread는 OS에 의해 직접 지원 받음.
- 어떤 Application 이든 Multi-Thread Programming이 가능함.
- Application 내의 모든 Thread는 Single Process 내에서 지원됨.
- Kernel은 Process 전체와 Process 내의 개별 Thread에 대한 Context 정보를 유지.
- Kernel 에 의한 Scheduling은 Thread 기반으로 Perform(수행).
- Kernel 은 Kernel 공간에서 Thread 생성, Scheduling 및 관리를 함.
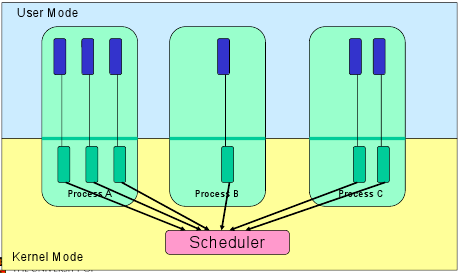
- Kernel Thread 장점
* Kernel 은 여러 Process의 동일한 Process에서 동시에 예약 가능
* Process의 한 Thread가 막히면 Kernel은 같은 Process의 다른 Thread를 Schedule 함.
* Kernel Routine 은 그들 자체로 Multi-Thread가 가능함.
- Kernel Thread 단점
* 보통 User Thread 보다 Create & Manage 속도가 느림.
* 같은 Process 내의 한 Thread에서 다른 Thread로 제어 이동하는건 Kernel의 Mode 전환이 필요함.
[3. Scheduling]
- Scheduling Process는 동작중인 Process를 CPU에서 제거하고, 특정 전략에 따라 다른 Process를 선택하는 일을 해야 할 Process Manage의 책임.
- 다중 Programming OS의 핵심 부분.
- 이런 OS는 한번에 둘 이상의 Process를 실행 가능 Memory에 로드 가능하며, Load된 Process는 시간 Multiplexing(다중화)를 통해 CPU를 공유.
- OS는 Processing Scheduling Queues에서 모든 PCB(Process Control Blocks)를 유지.
- OS는 각 Process 상태에 대해 별도의 Queue를 유지하며, 동일한 실행 상태에 있는 모든 Process의 PCB는 동일한 Queue에 배치.
- Process 상태가 변경되면 PCB가 현재 Queue에서 해제되고, 새 상태 Queue로 이동
- OS는 다음 3가지 중요한 Process Scheduling Queue를 유지함.
1) Job Queue : 이 Queue는 System에 모든 Process를 유지.
2) Ready Queue : Main Memory에 상주하는 모든 Process 집합체를 유지하고, Execute를 위해 대기.
3) Device Queue : I/O 장치를 사용할 수 없어 차단된 Process가 이 Queue를 구성.
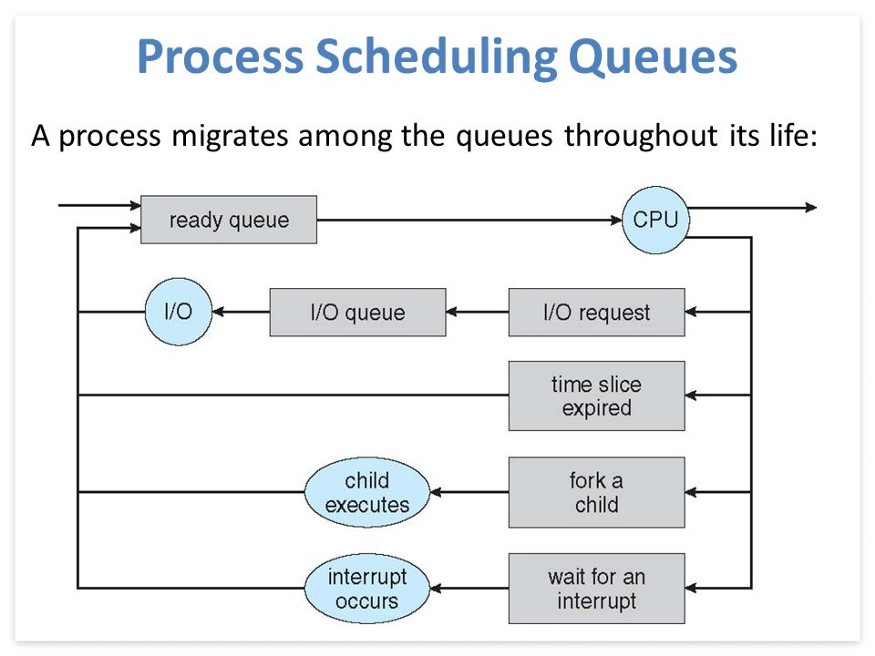
- OS 는 각 Queue(FIFO, Round Robin, Priority 등)을 관리하기 위해 서로 다른 정책을 사용 가능.
- OS Scheduler는 System Procss Core 당 하나의 항목만 가질 수 있는 Ready Queue와 Run Queue 간에 Process를 이동하는 방법을 결정.
- 상태(State) Model로는 Running와 Non-Running State가 있음.
1. Running : 새로운 Process가 생성되면 Running 상태의 System 안으로 들어감.
2. Not Running :
==> 실행되지 않는 Process는 Queue에 보관되어, 차례가 와서 Execute 되길 기다림.
==> Queue의 각 Entry(항목)은 특정 Process에 대한 Pointer.
==> Queue는 Linked List를 사용하여 Implement(시행) 됨.
==> Process가 중단되면 그 Process는 Waiting Queue로 이동.
만약 Process가 완료되거나 중단된 경우, Process는 버려짐.
두 경우 모두 Dispatcher는 Queue에서 실행할 Process를 선택.
- 한 Process에서 다른 Process로 전환하는 Context Switch.
==> Context Switch는 Process Control Block 에서 CPU의 상태 또는 Context를 저장하고 복원하는 Mechanism.
==> Context Switch를 통하여 나중에 동일한 지점에서 Process Execution을 재개 가능.
==> Context Switching은 OS Mult-Tasking의 핵심 특징.
==> Scheduler가 한 Process Executing에서 다른 Process로 CPU를 전환하면,
현재 Executing 중인 Process의 상태가 Process Control Block에 저장됨.
==> 이 과정을 거친 이후, 다음 Process 상태는 자체 PCB에서 Load 되어 PC, Register 등을 설정하는데 쓰임.
==> 이 지점에서 두번째 Process가 Executing 을 시작 가능.
* Process가 전환되면, 다음의 정보는 나중을 위해 저장됨.
==> Program Counter, Scheduling Information, Base and Limit Register Value, Currently Used Register,
Changed State, I/O State Information, Accounting Information
[4. Memory Management]
- Primary Memory를 다루거나 관리하는 OS의 기능.
- Execution 하는 동안 Main Memory와 Disk 사이에서 Process를 앞뒤로 이동시킴.
- Memory가 일부 Process에 할당되었든 자유롭게 사용가능하든 상관없이 모든 Memory 위치를 추적.
- Process에 할당될 Memory 양이 얼마나 될 지 확인.
- 어떤 Process가 어떤 시간에 Memory를 얻을지 결정함.
- Memory가 해제되거나 할당되지 않을 때마다 추적하고 그에 맞춰 상태를 업데이트.
* 관련 정보인 Process Address Space에 대해 보자.
==> Process가 Code에서 참조하는 논리 Address 집합체.
==> OS는 Program에 Memory를 할당할 때 논리 Address를 물리 Address로 Mapping.
==> Memory가 할당되기 전&후로 Program에서 사용되는 3가지 유형의 Address가 있음.
1) Symbolic Addresses :
- 주소는 Source Code에 쓰임.
- 변수명, 상수, 명령 Label 등은 Sysbolic Address의 기본 요소.
2) Relative Addresses :
- Compile 할 때 Compiler는 Symbolic Address를 Relative Address로 변환.
3) Physical Addresses :
- Loader는 Program이 Main Memory에 Load될 때 이 Address를 생성.
- Virtual(가상) 및 Physical(물리) 주소는 Compile-Time 및 Load-Time Address Binding Scheme(체계)에서 동일.
- Logical Address Space : Program에 의해 생성된 모든 논리 Address 집합체
- Physical Address Space : 이런 Logical Address에 해당하는 모든 물리 Address의 집합체
[5. Inter-Process Communication]
- 두 가지 유형의 Process가 있음. Independent & Cooperating.
* Independent : 다른 Process 실행에 영향 안 받음.
* Cooperating : 실행 중인 다른 Process에 영향 받음
* 계산 속도 & 편의성 & Module 기능 등을 고려하면 Independent가 더 효율적으로 Execute 하지 않음.
- Inter-Process Communication(IPC, 프로세스 간 통신) :
* Process가 서로 통신하고 작업 수행 시기를 서로 맞추는 Mechanism.
* IPC 는 Cooperating 유형에 가까움.
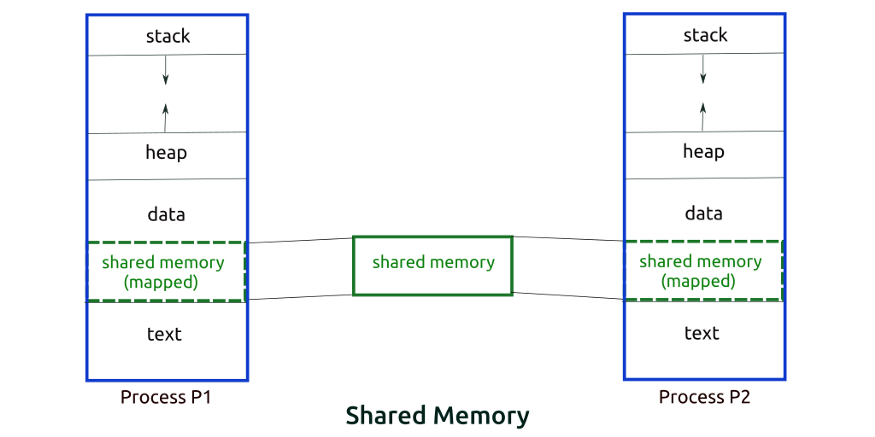
- Shared Memory Method
* 생산자와 소비자 Process 가 있다고 하자.
==> 생산자가 만든 Item이 저장되고 필요한 경우 소비자가 Item을 소비하는 Buffer 란 공통 공간 or Memory 위치를
두 Process가 서로 공유.
* 여기엔 두 가지 문제가 있음.
1) Unbounded Buffer Problem(무제한 버퍼 문제)
==> 생산자가 항목을 끝없이 생산 가능하며, Buffer 크기에 제한이 없음.
2) Bounded Buffer
==> 생산자는 Item을 특정 갯수까지 생산하며, 이후에 소비자가 Item을 소비하려고 대기.
==> 소비자는 먼저 Item을 쓰는게 가능한지 확인하고, Item이 없으면 소비자는 생산자가 생산할 때까지 기다림.
- Message Parsing Method
* Process는 어떤 Shared Memory도 쓰지 않고 서로 통신하는 방법.
* 두 Process p1 & p2가 서로 통신한다면 다음처럼 진행함.
==> 통신 Link를 설정 (Link가 이미 존재하면 설정할 필요 없음).
==> 기본 Primitive를 사용하여 메시지를 교환하기 시작. 여기선 최소 2가지 Primitive가 필요.
Send(Message, Destination) & Send(Message) & Receive(Message, Host) & Receive(Message)
==> 메시지 크기는 고정되거나 변함. 고정 크기라면 OS 설계자는 쉽지만 Programmer는 복잡. 변동 크기는 반대.
==> Standard(표준) 메시지는 Header와 Body로 구성.
==> Header는 메시지 유형, 대상 ID, Source ID, 메시지 길이 및 Control 정보를 저장.
==> Control 정보는 Buffer 공간이 부족할 때 수행 예정 작업, Sequence Number, Sequence Number의 우선순위 등을 포함.
==> 메시지는 FIFO 방식으로 전송.
[6. Input/Output Management]
- OS에 중요한 작업 중 하나는 마우스, 키보드, Disk Drive, Display Adaptor 같은 다양한 I/O 장치 관리.
- I/O System은 Application이 보낸 I/O 요청을 받아 Physical Device로 보내고,
Device에서 반환한 응답을 받아 Application으로 보냄.
- I/O Device 는 2가지 분류가 있음.
1) Block Devices :
==> Driver가 전체 Data Block을 전송하여 통신하는 Device.
==> 예시로 Hard Disk, USB Camera, Disk-On-Key
2) Character Devices :
==> Character Device는 Driver(Byte, Octet) 를 송수신하여 통신하는 Device.
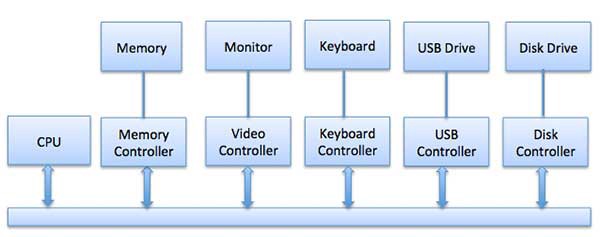
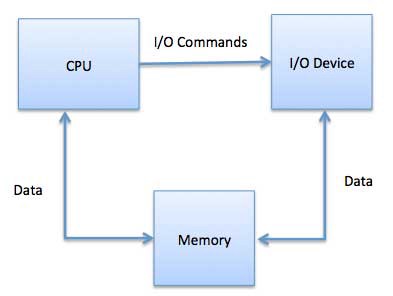
- CPU와 Device가 통신하는 3가지 접근법
1) Special Instruction I/O
* I/O Device를 제어하고자 특별히 만들어진 CPU Instruction(명령)을 사용.
* Instruction은 Data를 I/O Device로 보내거나, I/O Device에서 읽는게 가능하도록 함.
2) Memory-Mapped I/O
* 이걸 통해 동일한 Address 공간이 Memory 및 I/O 장치에서 공유.
* Device는 특정 Main Memory에 직접 연결되어, I/O Device가 CPU를 안 거치고 Memory 및 Data Block을 주고 받음.
* Memory-Mapped I/O를 쓰는 동안 OS는 Memory Buffer를 할당하고,
I/O Device에 해당 Buffer를 사용하여 Data를 CPU로 보내도록 알림.
* I/O Device는 CPU와 비동기식으로 작동하며, 완료시 CPU를 중단.
* 이 방식이 가진 장점은 Memory에 Access하는 모든 Instruction을 I/O 장치 조작에 사용함이다.
3) Direct Memory Access (DMA)
* 키보드 같은 느린 Device는 각 Byte가 전송 후 Main CPU에 Interruption을 생성.
* Disk 같은 빠른 Device가 각 Byte에 Interruption을 생성하면, OS는 Interruption 처리에 많은 시간을 소비.
* 보통 Computer는 Direct Memory Access(DMA) Hardware로 Overhead를 줄임.
* DMA는 Involvement(개입) 없이 Memory에서 Read/Write 하는 I/O Module 권한을 CPU가 부여함을 의미.
* DMA Module 자체는 주 Memory와 I/O Device 간 Data 교환을 제어.
* CPU는 전송의 시작&끝만 관여하며, 전체 Block이 전송된 후에만 Interrupt 됨.
* DMA를 위해 Data 전송 관리 및 System Bus Access를 중재하는 DMA Controller(DMAC) 란 Hardware가 필요.
* Controller는 Source 및 Destination(목적지) Pointer, 전송 Byte 숫자를 추적하는 Counter 및 다양한 설정으로 구성.
==> 여기엔 I/O, Memory 유형, CPU Cycle(주기)에 대한 Interruption & State 를 포함.
[7. Virtualization]
- Single한 Physical Hardware System에서 여러 Simulated 환경 혹은 Dedicated(전용) Resource를 생성.
- Hypervisor는 해당 Hardware에 직접 연결되어 하나의 System을 VM(가상 머신)로 분할.
==> VM은 Computer의 Resource를 Hardware에서 분리 및 적절하게 배포하는 Hiperviser 기능에 의존.
- HyperVisor가 장착된 본래 Physical System을 Host라 함.
- Resource를 사용하는 수 많은 VM을 Guest라 함.
==> Guest는 CPU, Memory, Storage 등 Computing Resource를 쉽게 재배치하는 Resource Hangar(격납고?).
- Operator는 Guest가 필요할 때 필요한 Resource를 받도록
CPU, Memory, Storage, 기타 Resource가 가진 Virtual Instance를 제어.
- 관련된 모든 VM은 속도를 높이는 '단일 Web 기반 VIrtualization(가상) 기능 관리 Console'로 관리.
- VIrtualization으로 VM에 제공하는 Processing Power, Storage 및 Memory Amount(양)을 지정.
- 여러 VM이 지원 기능 Hardware 및 각자가 서로 분리된 이유로 환경이 잘 보호됨.
- VIrtualization은 사용율이 낮은 Hardware로 부터 필요한 환경과 Resource를 생성.
- [Virtualization 유형]
1) Data
==> 곳곳에 흩어진 Data를 Single Source로 통합
==> 기업은 Data를 여러 Source Data를 통합 처리하는 Dynamic Supply로 취급하여,
새로운 Data Source를 쉽게 수용하고 User 요구에 따라 Data를 변환.
==> 필요한 Data를 적절한 형식으로 때에 맞춰, 모든 Application이나 User에게 제공.
2) Desktop
==> 중앙 Administer(관리자) 혹은 자동 관리 도구는
Simulate 된 Desktop 환경을 수백 대의 Physical System으로 한번에 배포.
==> 각 System에 Physical로 설치, 구성, 업데이트하는 기존 Desktop 환경과 달리,
Desktop 가상 기능으로 Administer는 모든 가상 Desktop에 대량 구성, 업데이트, 보안 검사를 수행.
3) Server
==> 수 많은 특정 작업을 효율있게 처리하도록 설계된 Computer.
==> Laptop 및 Desktop과 같은 다른 Computer에서 다양한 작업을 수행.
==> Server가 가상 기능을 가지면 이런 특정 기능을 더 많이 수행하며,
구성 요소를 사용하여 여러 기능을 제공하도록 Server를 분할.
4) Operating System
==> OS 중앙 작업 Manager인 Kernel 에서 발생.
==> Linux & Window 를 함께 실행하는데 유용.
==> 즉시 사용하는 기능을 필요로 하지 않아 Hardware Cost 절감
==> Virtual Instance를 모니터링 및 격리하여 보안 강화.
==> Software 업데이트 등 IT 서비스 사용시 발생하는 소요 시간을 제한.
5) Network Function
==> NFV 는 Network 주요 기능(e.g. Directory Service, File 공유, IP 구성)을 분리하여 환경들을 각기 분산시킴.
==> Software 기능이 예전에 있던 Physical System에서 독립하면,
특정 기능을 새로운 Network로 함께 Packaging 및 환경 할당.
==> 스위치, 라우터, Server, 케이블, Hub 등 독립 네트워크를 형성에 쓰이는 Physical Component의 수를 줄임.
[8. Distributed File Systems]
- Client가 마치 자기 Computer인 것 처럼 Server에 저장된 Data에 Access하고 처리 가능하게 하는 Client-Server 기반 Application.
- User가 Server의 File에 접근하면 Server는 User에게 Data가 처리되는 동안
User의 Computer에 Cache한 후 Server로 반환되는 File 복사본을 보냄.
- Distributed File System은 원격 Data Access가 특정 위치에 국한되지 않고,
모든 Client에서 동일한 방식으로 개별 Server의 File 및 Directory Service를 Global Directory로 구성.
- 모든 File은 Global File System의 모든 User가 Access할 수 있으며, 조직은 수직 계층구조 및 Directory 기반임.
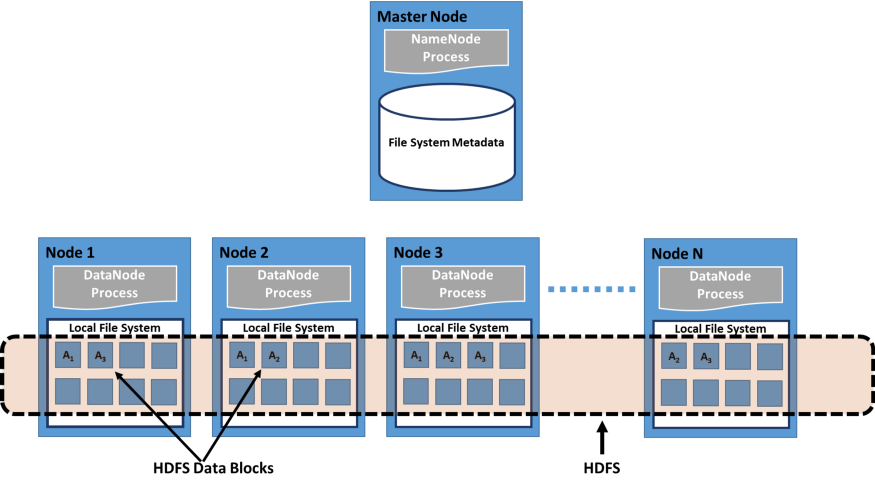
- 둘 이상의 Client가 동일한 Data에 대하여 동시에 Access할 수 있기에, Server는 업데이트를 구성하기 위한 Mechanism(Access 시간에 대한 정보 유지)이 있어야 함.
==> 이를 통해 Client는 항상 최신 Data를 수신받고, Data 충돌이 발생하지 않음.
- 보통 File or Database 복제(여러 Server에 Data 복사본 배포)를 통해 Data Access 실패를 방지.
[9. Distributed Shared Memory]
- 물리적 Shared Memory가 없는 Distributed System에서,
Shared Memory Model를 Implement(실행)하는 Distributed OS의 Resource 관리 구성 요소.
- Shared Memory는 Distributed System의 모든 Computer 간에 공유되는 가상 Address 공간을 제공.
- DSM에서 Data는 가상 Memory에 Access하는 방식과 유사한 공유 공간에서 Access.
- Data는 보조 Memory와 Main Memory 사이 뿐 아니라 서로 다른 노드의 Distributed Main Memory 사이를 이동.
- Memory의 페이지 소유권은 사전 정의된 상태에서 시작되지만, 정상 작동 과정에서 변경됨.
- 특정 Process의 Access로 인해 Data가 한 Node에서 다른 Node로 이동할 때 소유권 변경이 발생.
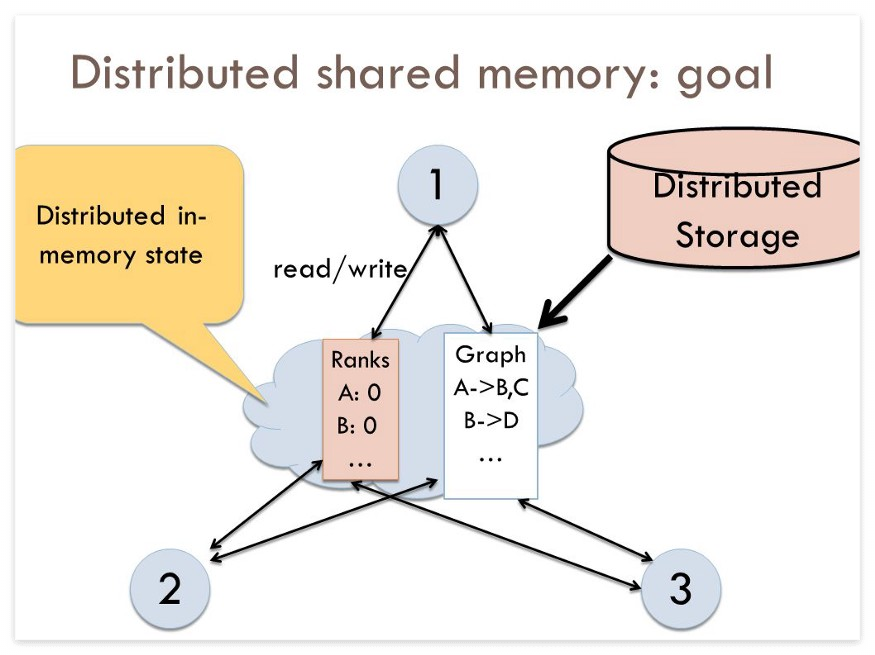
- DSM의 장점
* Data 이동을 숨기고 Data 공유를 위한 더 간단한 Abstraction을 제공.
* Programmer는 메시지 전달 Model을 사용할 때처럼 Computer 간의 Memory 전송에 대해 걱정할 필요가 없음.
* Data 조각이 아닌 참조 Data가 포함된 전체 Page를 이동하여 "Locality of Reference(참조 지역성)"의 이점을 가짐.
* Muti-Processor System보다 구축 비용이 저렴.
Idea(?)가 일반 Hardware를 통해 구현 가능하며, Shared Memory를 Process에 연결하는 과정에 복잡함이 없음.
* 모든 Node의 Physical Memory를 결합하여 더 큰 Memory 크기를 Program에서 사용 가능.
* Node를 무제한한 수(number)만큼 쓸 수 잇음.
* Shared Memory Multi-Processor로 작성된 Program은 DSM System으로 실행 가능.
- 누가 어떤 Page를 소유중인지 Node에 알리는 두 가지 방법이 있음.
1. Invalidation :
==> 일부 Process가 해당 Page에 대한 Write Access를 요청 후 새 Owner가 될 때, Page를 Invalidate(무효화) 함.
이로써 다음 번에 타 Process가 자신이 갖고 있다고 여긴 Page의 복사본을 Read/Write 할 때,
해당 Page를 사용할 수 없으며, Process는 해당 Page에 대한 Access를 다시 요청해야함.
2. Broadcast :
==> Process가 Memory Page에 Write할 때 Memory Page의 모든 복사본을 자동으로 업데이트 함.
==> 이 방법은 Invalidation 메시지 대신 새 Value를 보내야 하기에 훨씬 덜 효율적이고 구현이 어려움.
[10. Cloud Computing]
- Cloud Computing을 통해 사용자가 Data를 직접 소유하지 않고, Harware 및 Software에 대한 관리를 하지 않아도 된다는 말.
- (본인 주) 대체 이게 OS 동작원리와 무슨 상관성이 있어서 넣은거지?
<참조 2>
'Programing > OS' 카테고리의 다른 글
| [OS] Layered Operating System (OS 6 계층) (0) | 2022.12.11 |
|---|---|
| [OS] CPU vs GPU 차이 (0) | 2022.08.15 |
| [OS] Data Propagation (0) | 2022.08.11 |
| [OS] Cache Hit Ratio (0) | 2022.08.10 |


댓글